|
Всё, что когда-либо было написано рукой человека, уже в скором времени станет доступным на мониторе компьютера: так постепенно осуществляется мечта об универсальной электронной библиотеке. Книги постепенно уходят в прошлое, не выдерживая конкуренции с Интернетом, ведь в Сети можно практически моментально, не сходя с места, здесь и сейчас, получить информацию по конкретной теме. Но поисковики не всегда выдают подробную информацию, поэтому родилась мечта о создании полноценной бесплатной электронной библиотеки, которая включала бы в себя все существующие тексты. 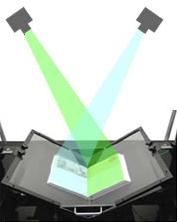 Автор проекта, компания Internet Archive, договаривается с библиотеками, нанимает копировальщиков и вместе со всем необходимым оборудованием отправляет их в библиотеки. Там копировальщики разворачивают свою сканерную станцию и принимаются за работу. Мастер кладет аккуратно развернутую книгу на особую подставку и опускает на страницы стеклянные пластины, смонтированные буквой V. После нажатия на специальную педаль опускаются две камеры, каждая из которых фотографирует по странице разворота. V-пластины поднимаются, мастер переворачивает страницу и снова фотографирует разворот. Так оцифровывают книги, за одну 8-часовую смену мастер копирует около 4.000 страниц. Автор проекта, компания Internet Archive, договаривается с библиотеками, нанимает копировальщиков и вместе со всем необходимым оборудованием отправляет их в библиотеки. Там копировальщики разворачивают свою сканерную станцию и принимаются за работу. Мастер кладет аккуратно развернутую книгу на особую подставку и опускает на страницы стеклянные пластины, смонтированные буквой V. После нажатия на специальную педаль опускаются две камеры, каждая из которых фотографирует по странице разворота. V-пластины поднимаются, мастер переворачивает страницу и снова фотографирует разворот. Так оцифровывают книги, за одну 8-часовую смену мастер копирует около 4.000 страниц.
Одна такая сканерная станция расположена в Ричмонде, в здании библиотеки Калифорнийского университета. Здесь 11 человек, отгороженные друг от друга светонепроницаемыми занавесками, сканируют книги с 8 часов утра до 12 часов ночи. Здесь никогда не разговаривают, ведь работа требует сосредоточенности. Когда вся книга скопирована, номера страниц сверяются, потому что самая распространенная ошибка – переворот сразу двух или нескольких страниц. Такая монотонная работа подходит не каждому, и 20% новичков отсеиваются уже через неделю. Монахи современной эпохи Эти мастера у сканеров – монахи цифрового века. Средневековые монахи, которые переписывали книги для следующих поколений, назывались писцами (scribes). А в Ричмонде, наоборот, сканеры называются «писцами» (scribes), а мастера – копировальщиками (scanners). Эти копировальщики играют главную роль в новом амбициозном проекте по созданию цифровой библиотеки будущего. Цель проекта состоит в том, чтобы отсканировать, «распознать», превратить в текстовые файлы и разместить в Интернете все, что когда-либо было напечатано человеком. Авторы проекта хотят опубликовать не только оцифрованные книги, они собираются пойти еще дальше и собрать мультимедиа-файлы с репродукциями произведений искусства, музыкальными записями и фильмами.  Отснятый из файлов текст распознается через файн-ридер (Fine Reader), преобразуется в текстовые данные и отправляется в Сеть. К сожалению, никто не сверяет «распознанный» текст с оригиналом, для компании это было бы слишком дорого. Отснятый из файлов текст распознается через файн-ридер (Fine Reader), преобразуется в текстовые данные и отправляется в Сеть. К сожалению, никто не сверяет «распознанный» текст с оригиналом, для компании это было бы слишком дорого.
Проект Internet Archive уже создал второй по величине литературный архив мира, и одновременно самый большой бесплатный архив в мире Компания отсняла уже 350.000 книг: это лишь около 1% мировой литературы, но среди скопированных книг есть очень важные, о существовании которых обычный человек даже и не подозревает. Было время, были книги Последняя универсальная библиотека находилась в античной Александрии Египетской. Каждый корабль, пристававший к александрийской гавани, должен был бесплатно предоставить библиотеке находящиеся на борту свитки с текстами. Служители библиотеки старательно копировали эти тексты и возвращали капитану. В эпоху своего расцвета античная библиотека располагала копиями 40% всех доступных в то время текстов. Но при обороне Александрии в 1 веке до нашей эры Цезарь приказал сжечь библиотеку, из всего собрания которой уцелели только вавилонские глиняные таблички. За два последующих тысячелетия было написано огромное количество текстов. Человечество произвело больше 30 миллионов наименований книг, многие из которых существуют только в нескольких экземплярах и разбросаны по тысячам библиотек мира. «Осиротевшие» тексты  15% книг можно без особых проблем оцифровать и разместить в сети Интернет для свободного просмотра. Авторские права на них давно истекли, так что составить архив таких текстов, как например, трагедий Шекспира или Гёте, – дело техники. Еще 10% книг опубликованы различными издательствами и находятся в продаже. Копировать такие тексты без согласия издательства и размещать их в бесплатном онлайн доступе было бы кражей интеллектуальной собственности. А чтобы получить разрешение издателя, придется заплатить немалую сумму. Поэтому такие книги пока не размещают в Интернет-библиотеках. 15% книг можно без особых проблем оцифровать и разместить в сети Интернет для свободного просмотра. Авторские права на них давно истекли, так что составить архив таких текстов, как например, трагедий Шекспира или Гёте, – дело техники. Еще 10% книг опубликованы различными издательствами и находятся в продаже. Копировать такие тексты без согласия издательства и размещать их в бесплатном онлайн доступе было бы кражей интеллектуальной собственности. А чтобы получить разрешение издателя, придется заплатить немалую сумму. Поэтому такие книги пока не размещают в Интернет-библиотеках.
Главная проблема – оставшиеся три четверти литературного наследия. Они уже не печатаются издательствами (к примеру, упал интерес читателей), но срок действия авторских прав еще не истек. Такие книги можно найти только в библиотеке, у букиниста или на запылившихся бабушкиных полках. О том, чтобы оцифровать именно такие «осиротевшие» книги, мечтали основатели Internet Archive, но они сдались. Гордиев узел разрубила компания Google, которая с 2004 года вкладывает деньги в промышленное сканирование книг. Агенты компании на грузовике приезжают в библиотеку, где хранятся «книги-сироты», грузят их в машину и везут на скан-фабрику. Чтобы не возникло неожиданных проблем с авторскими правами, месторасположение фабрики скрыто. Весь отсканированный материал включают в сетевой архив Google, уже насчитывающий около миллиона книг. Тексты, авторские права на которые уже истекли, можно просматривать свободно.  «Осиротевшие» книги находятся в ограниченном доступе: пользователю предлагаются несколько отрывков из книги и ссылка на библиотеку, в которую придется ехать, если книга пробудила интерес. Скопированные книги, всё еще находящиеся в продаже, также недоступны полностью, здесь сервер опять-таки предоставит только адрес библиотеки. «Осиротевшие» книги находятся в ограниченном доступе: пользователю предлагаются несколько отрывков из книги и ссылка на библиотеку, в которую придется ехать, если книга пробудила интерес. Скопированные книги, всё еще находящиеся в продаже, также недоступны полностью, здесь сервер опять-таки предоставит только адрес библиотеки.
Так что, пока Internet Archive грезит о цифровой Александрии, Google практично подходит к делу: у компании есть имя, которому доверяют библиотеки, и деньги, благодаря которым сканирование поставлено на поток. Информационному гиганту не препятствуют даже судебные процессы. Если кто-то считает, что авторские права нарушены, и подает жалобу, компания просто удаляет спорную книгу с сервера.
Илья Яковлев
www.Salon.Su |